
Every GKE platform team I talk to lands somewhere on the same spectrum. On one end are the curators: they hand-build node pools, tune every kubelet flag, pin the machine type to a reservation, and they do not want anything provisioning nodes they didn’t bless. On the other end are the automators: they never want to see a node pool again, and they’ll trade a little control for capacity that just shows up when a workload needs it.
Here’s the thing I want platform teams to internalize: with ComputeClasses, that’s a false choice. A ComputeClass sits happily on top of node pools you curate by hand and node pools GKE creates for you — often in the same spec. The interesting question isn’t “which one,” it’s “which one for this priority, and why.”
This is a follow-up to the ComputeClasses primer; if you’re new to the abstraction, start there.
Two surfaces, one abstraction#
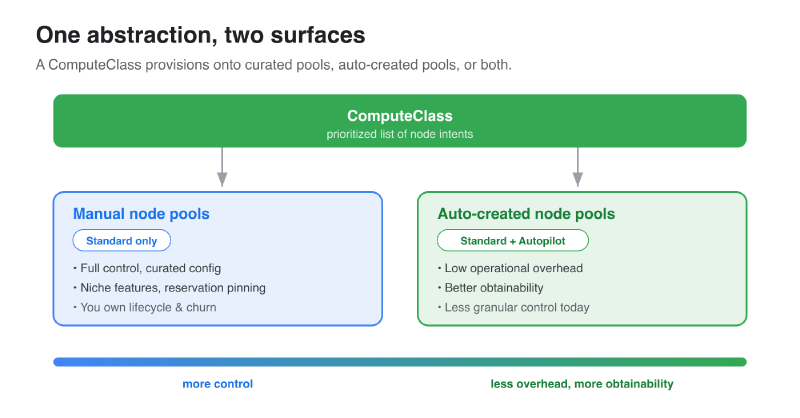
Quick recap. A ComputeClass is a prioritized list of node intents. What it provisions those intents onto can be either of two surfaces:
- Manually-created node pools you build and own (GKE Standard).
- Auto-created node pools GKE provisions on demand, scoped to the ComputeClass (Standard and Autopilot).
The same class can reference both. So the real decision is per-priority: for this tier of capacity, do I want a pool I curated, or one GKE conjures for me?
Manual pools: when you want control#
Reach for a manually-created node pool when the configuration matters more than the convenience. A pool you build by hand gives you the full surface area:
- Exact, curated configuration — node system config, kubelet tuning, a specific boot disk or networking setup, compact placement for tightly-coupled work.
- Features auto-creation doesn’t create for you yet. If a capability isn’t available through node pool auto-creation today, a manual pool is how you get it now.
- Tight reservation / committed-use alignment. You can pin a pool to a specific reservation and know exactly which committed capacity it draws from.
The trade-off is real, though: you own that pool’s whole lifecycle. You sized it, you patch its assumptions, and when you recreate or rename it, anything wired to it by name has to be rewired. Control has an operational tax.
Auto-created pools: when you want low overhead and obtainability#
Reach for auto-creation when you’d rather not babysit inventory. Turn on nodePoolAutoCreation, and the ComputeClass provisions pools scoped to itself, on demand:
- No pre-provisioning. You don’t guess shapes and pre-build pools to catch demand that may never come.
- Better obtainability. When your preferred capacity is tight, GKE can fall through your priorities and create something that satisfies the workload, instead of leaving Pods Pending against a pool you forgot to scale.
- Less to operate. No pool lifecycle to own. The class is self-contained.
The trade-off today is granularity: auto-creation covers the common shapes and the settings most workloads need, and there are still curated edges it doesn’t reach. (Hold that thought — it’s where this is all heading.)
| Manual node pool | Auto-created node pool | |
|---|---|---|
| Best when | full control / curated config is the point | low operational overhead + obtainability win |
| You get | every knob, niche features, exact reservation pinning | on-demand pools, graceful fallback, nothing to babysit |
| You pay | lifecycle + churn is yours to manage | less granular control today |
| Modes | Standard | Standard + Autopilot |
The move: use both in one class#
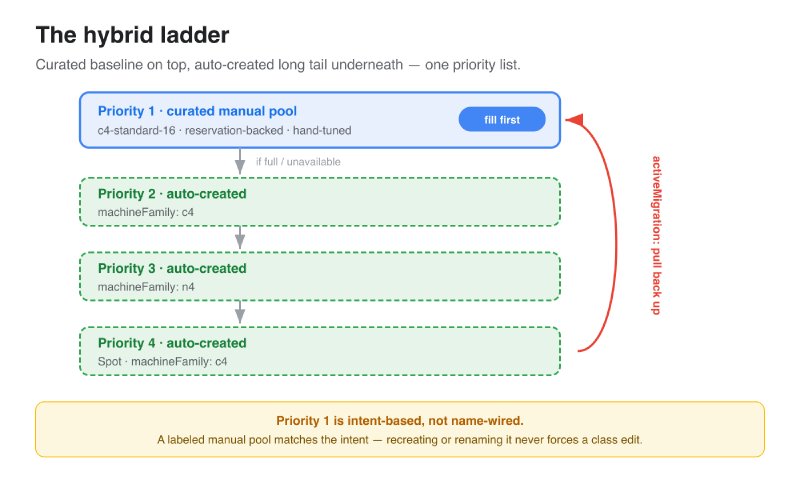
You don’t have to pick globally. The pattern I point most teams to is a curated baseline on top, auto-created long tail underneath — expressed as one ordered priorities[] list:
apiVersion: cloud.google.com/v1 kind: ComputeClass metadata: name: hybrid-capacity spec: nodePoolAutoCreation: enabled: true # only the fallback tiers auto-provision priorities:
1) Curated, pre-created baseline — reservation-backed, tuned by hand.#
- machineType: c4-standard-16 spot: false
2) Long tail (auto-created) for safety / obtainability.#
- machineFamily: c4 minCores: 8
- machineFamily: n4 minCores: 8
- spot: true machineFamily: c4 minCores: 8 activeMigration: optimizeRulePriority: true # pull back onto the baseline when it frees whenUnsatisfiable: ScaleUpAnyway
Pods fill your curated, reservation-backed pool first. When it’s full or unavailable, GKE walks the list and auto-creates generic fallback capacity so nothing sits Pending. When the baseline frees up, activeMigration pulls workloads back onto it.
There’s one subtlety that makes this durable, and it’s worth stating plainly: the top priority above is intent-based — machineType: c4-standard-16, not a pool name. A manual pool opts into the class by carrying its label and taint:
| |
Once labeled, the autoscaler evaluates that intent rule against your existing matching pools first. You can name pools explicitly with a nodepools: [reserved-c4-pool] rule — but then renaming, recreating, or blue-green-rolling that pool means editing the class. The intent form keeps working as long as the replacement carries the same label and matches. Declarative intent in, no manual rewiring.
I put a complete, runnable version of this in the examples repo — see hybrid-pools, alongside a dozen-plus other ComputeClass patterns.
Where this is heading: parity#
I’ll be straight about the direction, because it should shape how you invest. The reason to reach for a manual pool today is the curated edge — the knobs and niche features auto-creation doesn’t cover yet. That gap is closing. We’re actively working toward full parity, so that auto-created node pools are just as powerful as the ones you’d build by hand — same configurability, none of the lifecycle tax.
I won’t put dates on it here. But the north star is clear: auto-creation is the way of the future. So my advice is to bias toward auto-creation, lean on labeled manual pools for the genuinely-not-yet-supported cases, and prefer intent-based references over name-wiring so that when parity lands — and when your pools churn in the meantime — you’re not rewriting your classes to take advantage of it.
Recap#
The mental model: a ComputeClass is one abstraction over two surfaces. Curate manual pools where control is the point, auto-create where overhead and obtainability win, and combine them in a single priority list when you want both. Reference everything by intent so it survives churn — and so it’s ready for a future where auto-creation does it all.
The full field reference lives in the ComputeClass CRD docs. More in this series soon.